La automatización de unidades de información, a lo largo del tiempo ha variado desde el punto de vista tecnológico, técnico y documental. Desde su implantación estable a partir de 1990, las bibliotecas, archivos y museos, inicialmente utilizaron sistemas ad-hoc con bases de datos documentales. Esto significaba la inexistencia de normalización en los procesos documentales y la imposibilidad de vincular y relacionar los catálogos bibliográficos y la descoordinación con respecto a los centros de gestión de los que dependían. En España los continuos programas de I+D+I lograron impulsar inicialmente una automatización y adaptación a las nuevas tecnologías de las redes de bibliotecas universitarias, redes de archivos y museos. En un segundo momento, los programas de desarrollo de la sociedad de la información en la Unión Europea, más conocidos como Frameworks programmes, han impulsado el desarrollo e implantación de sistemas de gestión con mayor proyección y nivel de normalización. En un contexto de incipiente actualización y mejora de los sistemas de automatización ya desarrollados, se procuran diseñar modelos con bases de datos relacionales e híbridas así como lenguajes de programación orientados a su empleo en la red, a fin de mejorar las posibilidades y prestaciones de los servicios de consulta y recuperación de información.
Soportes de los sistemas de gestión de UIDs
Los sistemas de gestión de unidades de información y documentación, normalmente emplean un modelo tecnológico basado en la arquitectura cliente-servidor. Se considera fundamento tecnológico porque ofrece las bases y soportes de instalación necesarios para que el sistema ofrezca sus servicios en el ámbito de una red.
Qué es la arquitectura cliente-servidor
La arquitectura cliente servidor consiste en la disposición de dos elementos fundamentales. Por un lado un equipo servidor también denominado Host o esclavo, y un equipo cliente o amo. El equipo o equipos servidores, constan de una serie de soportes o programas que les permiten ofrecer una serie de servicios, ante las peticiones de los clientes que están conectados a su red. Un equipo cliente por su parte puede establecer conexión con una red de servidores de los que recibe servicios mediante protocolo TCP/IP. Estos servicios se producen gracias a las peticiones que se remiten al servidor. Los servicios de conexión a Internet, correo electrónico, acceso a bases de datos en red, mensajes, transmisión de datos utilizan este tipo de arquitectura. También es importante destacar que la arquitectura cliente servidor se caracteriza por ser multicapa, pudiendo diversificar las tareas del servidor en diversas máquinas de la red, reduciendo la carga de transacciones de la misma.
Para comprender mejor el propósito de la arquitectura cliente-servidor, aquí se adjunta un esquema que ayudará a conocer los elementos de un caso genérico, que se corresponde con el de las prácticas que se llevarán a cabo durante la asignatura.
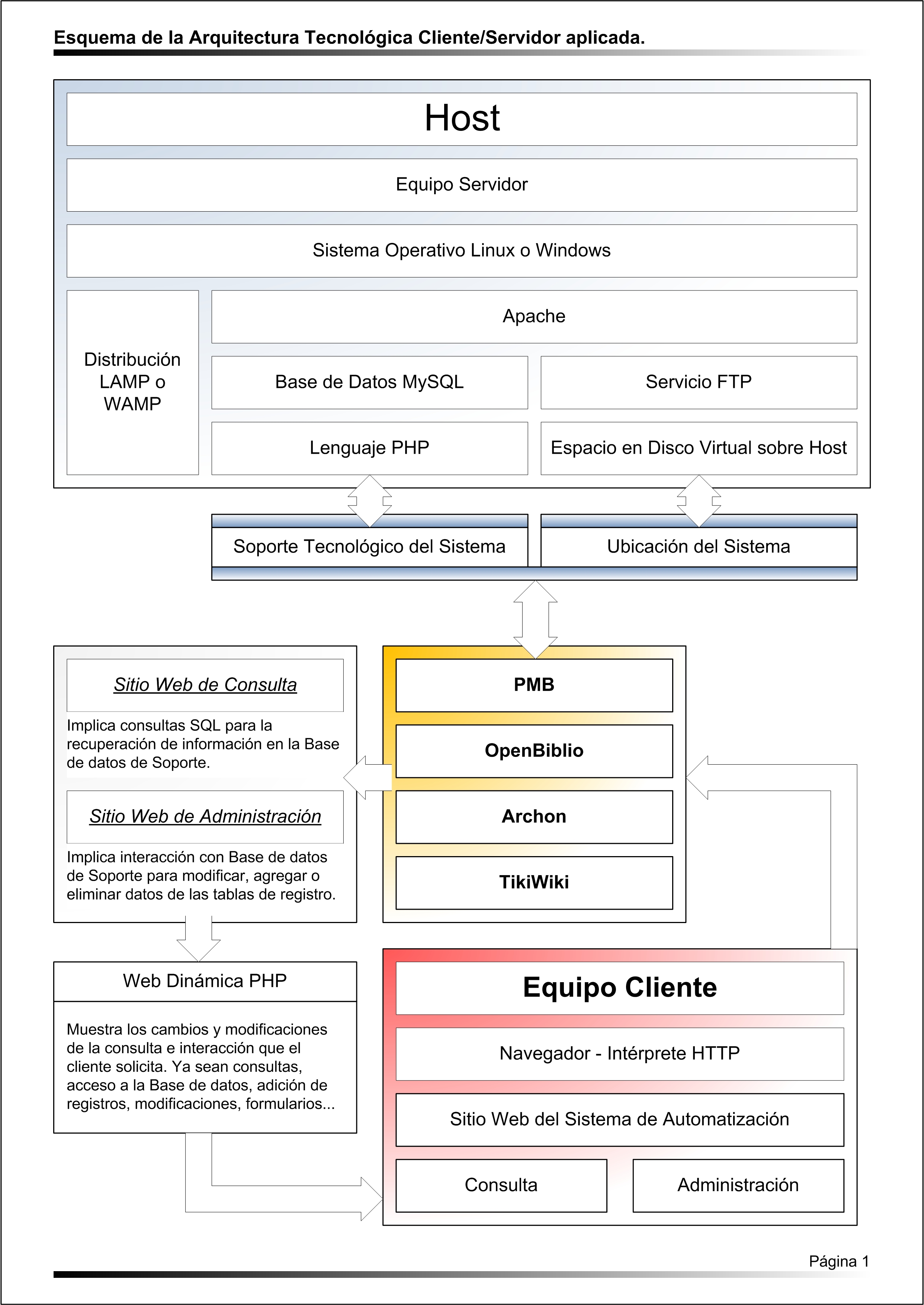
Explicación del Esquema
En este esquema se puede comprobar la existencia de dos bloques principales, tal y como se viene advirtiendo en la explicación anterior. El funcionamiento de este modelo se basa en un equipo servidor que dispone de una plataforma o sistema operativo Linux/GNU o Windows. Habitualmente se suele emplear Linux o las variantes de Unix, dada su estabilidad y seguridad frente a los servidores que instalan Windows Server. En cualquier caso ambas posibilidades son factibles. Si se observa bien, debajo de la capa del sistema operativo, aparecen diversas capas que son consideradas como distribución WAMP o LAMP dependiendo del sistema operativo que utilice el servidor. WAMP es aquella distribución del servidor constituida por Windows, Apache, MySQL y PHP. LAMP es similar a WAMP, con la diferencia de que la "L" corresponde a una máquina linux. El elemento común de base en estas distribuciones es el programa servidor Apache. Sobre apache se instala la base de datos MySQL, el módulo del lenguaje PHP, y el módulo FTP para permitir servicios de transferencia de archivos al disco virtual de la máquina donde está instalado el servidor. En el esquema se diferencia por un lado la triada formada por Apache, MySQL y PHP que permite la operatividad de los sistemas de gestión y automatización que queremos instalar e implantar y por otro lado el binomio formado por Apache y el módulo de FTP que viene a dar acceso al espacio en disco para ubicar las aplicaciones que funcionarán del lado del servidor.
Esto significa que para el correcto funcionamiento de estos sistemas de automatización, se necesita un espacio de instalación que es donde reside virtualmente y los soportes tecnológicos descritos, Apache para permitir el acceso de la aplicación en la red, MySQL como base de datos matriz que soporta las tablas de datos del sistema y PHP como módulo de lenguaje para interpretar las páginas y consultas que desde la web un cliente pueda llegar a ejecutar.
Es importante también recordar el detalle de que estos sistemas se ejecutan desde el lado del servidor, porque constituyen en sí mismos un servicio más que ofrece la máquina esclava. El equipo cliente siempre visualiza los resultados de sus acciones que son ejecutadas en el servidor. Nunca en su propia máquina. El funcionamiento de estas capas en la arquitectura cliente-servidor y en especial en el desarrollo de sistemas de gestión para la automatización de unidades de información, supone una gran ventaja de deslocalización y redistribución de los puntos de acceso a este tipo de servicios.
En referencia al cuadro amarillo, se denotan los sistemas de automatización que se estudiarán en esta asignatura y que funcionan con estos mismos esquemas y fundamentos tecnológicos. No son los únicos. La gran mayoría de los sistemas de gestión de bibliotecas, archivos, centros de documentación y museos, utilizan esta variante o diferentes de este tipo de arquitectura tecnológica. Las principales cambios se producen a nivel de base de datos; por ejemplo en vez de MySQL, se puede llegar a utilizar ORACLE, dBase, DB2, PostgreeSQL, Firebird . En vez de PHP, en servidores Windows, se suele emplear ASP. En vez de Apache, Apache Jakarta (Servidor orientado a Bases de Datos Oracle), Apache Tomcat (servidor para objetos y páginas dinámicas java o lo que se denomina servlet y JSP).
En referencia al cuadro rojo, se representa el equipo cliente con su arquitectura habitual con el correspondiente intérprete http o navegador para acceder a las páginas de acceso y administración de los sistemas de automatización que se encuentran el cuadro amarillo. El simple acceso a estas páginas de tipo dinámico, programadas en PHP, suponen una petición del cliente al servidor. Dicha petición es procesada por el servidor Apache, que la resuelve presentando la página pedida. En los casos en los que las peticiones suponen una interacción con la base de datos del sistema de gestión o una acción concreta dentro del grupo de páginas PHP que articulan el sistema de gestión, Apache utiliza los módulos que tiene instalados para permitir la modificación de los parámetros, datos, registros y archivos según las instrucciones del cliente. Esto quiere decir que una modificación en la base de datos debida a la introducción de un nuevo registro, se contempla en la programación de la página web que se visualiza para controlar el sistema. Esta instrucción es interpretada por los módulos de sql y php que Apache incorpora y que permiten dar la orden de introducción de datos que pidió el cliente en la base de datos de soporte MySQL. El proceso no acaba hasta que esa instrucción se cumple, renovando la información actualizada al usuario con los cambios realizados en la página web de su navegador. Tal y como se puede comprobar existe una comunicación continua entre el cliente y el servidor utilizando como puente de transmisión los fundamentos tecnológicos que hemos expresado.
Cliente-Servidor en una Unidad de Información y Documentación
La arquitectura cliente-servidor puede emplearse y de hecho se emplea en el contexto de las Unidades de Información y Documentación. Una UID, puede tener múltiples puntos de acceso al sistema de gestión bibliotecario a modo de clientes, dependientes de un servidor dedicado. A continuación se muestra un esquema que ayuda a entender este concepto.
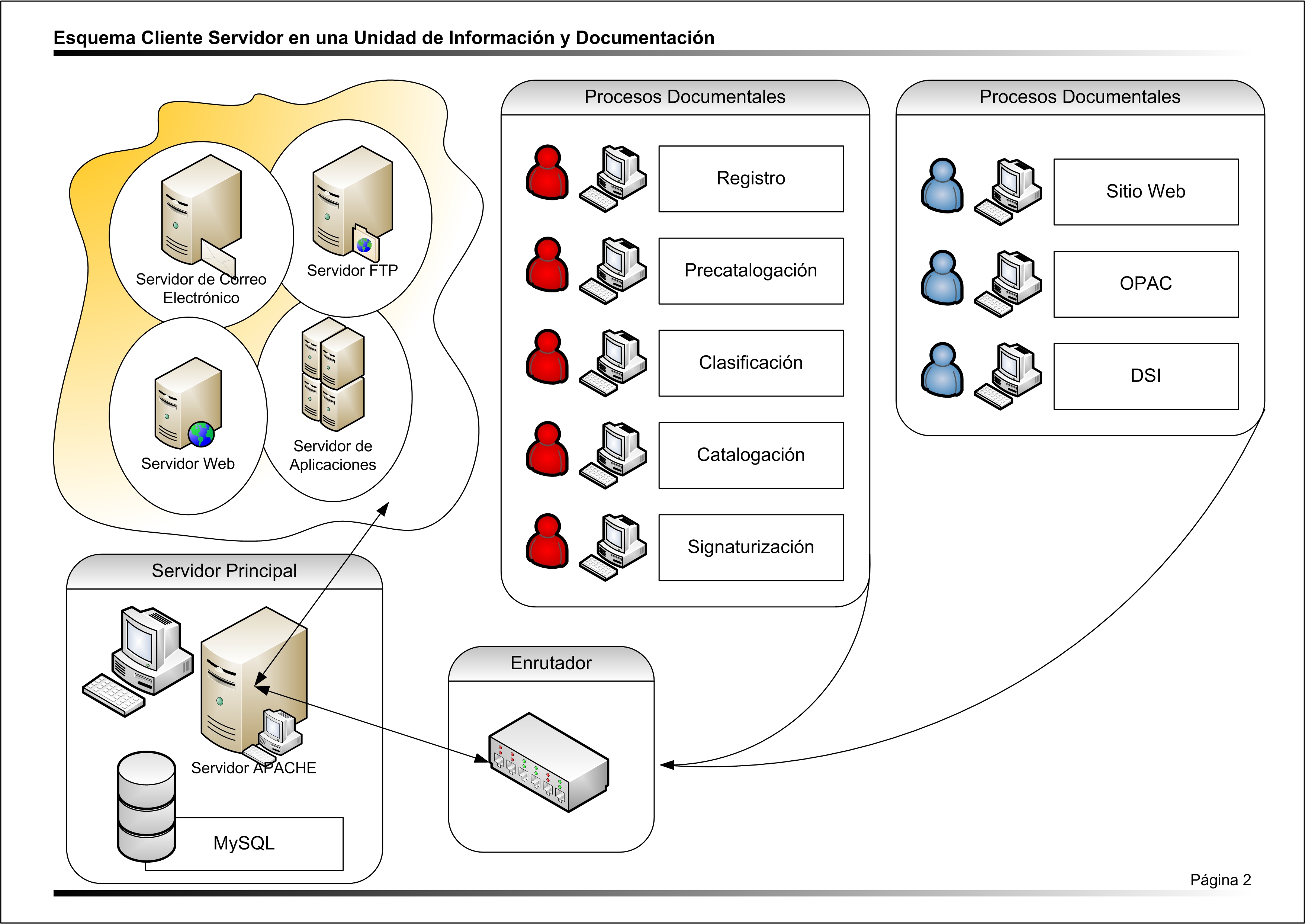
En este esquema se representa un nivel de servidores que están dedicados a servicios especializados como el correo electrónico, el servicio ftp, servicio web, servicio de aplicaciones y un servidor principal de administración con el que establecen una red delimitada y accesible. Es importante recordar que la arquitectura cliente servidor puede efectuarse con uno o más Hosts o servidores que pueden compartir o especializarse en relación a los servicios que tienen encomendados. En este caso disponen de una base de datos MySQL, Servidor Apache y un servidor dedicado a la instalación de los sistemas de automatización de la unidad de información y documentación. Los servicios de la UID, son suministrados a los clientes, que en este caso son los profesionales que trabajan en el centro desempeñando una serie de actividades y procesos documentales (Registro, Precatalogación, Clasificación, Catalogación, Signaturización...) Que pueden conformar un modelo de cadena documental. Por otro lado también son considerados equipos clientes, los utilizados por los usuarios del centro de información. Los servicios de OPAC, Recuperación de Información, Información y Referencia del Sitio Web de la Biblioteca, así como el sistema de Difusión Selectiva de la Información que pueden llegar a utilizar, también se nutre a partir de los mismos servidores que suministran las aplicaciones de trabajo de los profesionales del centro.
GLOSARIO
Host
- Es cualquier máquina conectada en red, con funciones de servidor y por lo tanto de manera remota, que desempeña una serie de servicios desde una dirección IP. Estos servicios pueden variar desde el FTP para acceder a un disco virtual sito en dicho host a ofrecer soporte de interpretación de páginas web programadas en PHP, e incluso servicios de soporte de bases de datos como MySQL.
Dirección IP
- Se denomina dirección IP al número que identifica unívocamente a cualquier máquina, Host o servidor conectado a una red. Éstas pueden ser fijas o dinámicas.
- Son IP fijas cuando son suministradas directamente por un proveedor ISP (Internet Service Provider). Es el caso de los Host como el explicado en el esquema. Esta condición permite mantener un servicio de conexión unívoco que evita la actualización constante de los datos de conexión al servidor.
- Se considera a una IP dinámica, cuando es suministrada por un servidor DHCP (Dynamic Host Configuration Protocol). Dicho servidor proporciona a nuestra máquina cliente una dirección IP que varía cada cierto tiempo según quedan disponibles en la terna que suministran. Es el caso de la conexión a Internet, que habitualmente funciona de esta forma.
- Cualquier equipo puede configurarse como un Host de prueba en modo local y por tanto referirse a él mismo. Esto permite probar cualquier sistema de automatización que trabaje con una arquitectura cliente/servidor como la descrita en el esquema. En estos casos el IP es 127.0.0.1 y su nombre de espacio o NAMESPACE se denomina “localhost”. Esta forma de configurar el equipo se llama Loopback o Interfaz de red virtual.
- Se denomina un equipo servidor cuando mantiene instalado un software capaz de atender las peticiones de equipos clientes. Estas peticiones pueden variar entre peticiones de páginas web, de transferencia de archivos, transmisión de mensajes, operaciones en bases de datos, etc. Dicho de otra forma permite establecer comunicación con las aplicaciones que tiene instaladas para llevar a cabo las tareas que sean necesarias en beneficio de una respuesta para el cliente, en función de la petición.
- Existen servidores multifunción y dedicados. Uno de los más polivalentes y extendidos es Apache, dadas sus posibilidades de combinación con los principales fundamentos tecnológicos del desarrollo web. De esta forma un servidor de dichas características es capaz de proporcionar servicios de Correo, FTP, Soporte Web, Soporte de Bases de Datos, Conexión a Internet, Red P2P, entre otras.
- LAMP son las iniciales de Linux, Apache, MySQL y PHP. Conforman una distribución de servidor Host, bajo la que funcionan multitud de servicios en red. También se denomina LAMP aquella técnica de desarrollo web específicamente diseñada para dichos soportes.
- WAMP son las iniciales de Windows, Apache, MySQL y PHP. Conforman al igual que LAMP una distribución de servidor Host, bajo la que funcionan multitud de servicios en red. Se denomina igualmente WAMP aquella técnica de desarrollo web específicamente diseñada sobre este soporte.
- Es el principal servidor Web de código libre, diseñado para funcionar en la mayoría de las plataformas y sistemas operativos basados en Unix o Windows.
- El servidor Apache implementa el protocolo HTTP o lo que es lo mismo el protocolo de transferencia hipertexto que permite el funcionamiento de la red.
- Apache permite el empleo de módulos que conforman servicios que se circunscriben en el ámbito http de la web. Éstos son algunos de los más importantes; 1) SSL o Secure Socket Layer (Módulo para incorporar protocolo de transmisión de datos mediante capa de seguridad criptográfica); 2) Módulos Perl, Php, Python, Ruby que permiten la interpretación de Scripts editados en estos lenguajes; 3) Módulos mbox, pop3 y smtpd, para incorporar protocolos de correo electrónico.
- MySQL es la base de datos con mayor difusión en todo el mundo. Es de tipo relacional multiusuario, polivalente con la mayoría de los sistemas operativos y soportes disponibles actualmente. Es realmente apreciada por su capacidad de adaptación a PHP y la sencillez de operar con sus elementos para representarlos a modo de consultas o scripts en lenguaje SQL. También puede operar de manera embebida, funcionar como base de datos dedicada o distribuida. Esto le confiere una gran capacidad de adaptación a entornos de red. Es utilizada esencialmente para la gestión de grandes sitios web, gestión de documentación, colecciones bibliográficas, catálogos, colecciones de archivos principalmente en un entorno virtual. Carece de limitaciones de espacio en la longitud de campos por lo que resulta muy flexible de adaptar a las necesidades de un centro de documentación. Se pueden crear tantas tablas, campos y longitud de campo como sea necesario.
- PHP o Hypertext Pre-Procesor es el lenguaje de programación que se utiliza para la confección de páginas web dinámicas. Permite incorporar Scripts para consultas en SQL que permiten interrogar fácilmente a bases de datos del tipo MySQL. Es compatible con la mayor parte de los soportes tecnológicos.
2 comentarios:
Que buen Blog, es muy interesante que personas en esta área del conocimiento tan importante para la sociedad actual esté inmersa en temas como éste, ya que son temas que nos atraen y que cada vez son más compatibles con nuestros fines de recuperación de información.
img src="http://www.librarytechnology.org/images/automationhistory2010b.jpg" border="0" alt="Graphic history of the history of library automation
by Marshall Breeding"
Publicar un comentario